Redakcja: dondu

1. Zadanie
Ze względu na wybór generatora liczb pseudolosowych zmodyfikowałem nieco założenia zadania. Modyfikacja polegała na tym, że zrezygnowałem z jakichkolwiek elementów zewnętrznych i ze zmiennej globalnej liczba_RND. Zmienna globalna w implementacji jaką przedstawiam w dalszej części tego rozwiązania zakłada użycie funkcji zwracającej liczbę losową. Dlatego uznałem, że taka zmienna globalna jest zbędna.
Baza sprzętowa
Ze względu na wybór implementacji nie potrzebującej, żadnych elementów zewnętrznych bazę sprzętową stanowi właściwie sam mikrokontroler atmega8 plus elementy niezbędne do jego poprawnego działania. Schemat użytego układu znajduje się tutaj (wersja 1): Minimalne podłączanie pinów
Warto wspomnieć, że do akwizycji danych został wykorzystany układ USART. Trudno jest mi sobie wyobrazić, żeby ktoś zachował zdrowie psychiczne po ręcznym przepisaniu miliona lub dziesięciu milionów liczb losowych. Rolę pośredniczącą pełniła przejściówka oparta na układzie scalonym FT232RL firmy FTDI.
2. Wybór rozwiązania i teoria
Według [1] istniejące rozwiązania w temacie generowania liczb losowych można podzielić na dwa podstawowe typy:
- Generatory sprzętowe (ang. TRNG - True Random Number Generator)
- Generatory programowe (ang. PRNG - Pseudo Random Number Generator)
Generatory sprzętowe opierają się jak sama nazwa wskazuje na rozwiązaniach sprzętowych. Zazwyczaj nową liczbę losową otrzymuje się poprzez pomiar jakiejś wielkości fizycznej, którą charakteryzuje nieprzewidywalność. Taką wielkością może rejestracja rozpadu jakiejś cząstki. Najczęściej wykorzystywaną wielkością, ze względu na prostotę, jest szum elektryczny [1].
Generatory programowe nie są w stanie wytworzyć prawdziwie losowych liczb, dlatego w literaturze występują jako generatory liczb PSEUDOlosowych. Ta pseudo losowość wynika z tego, że komputer jest maszyną ściśle deterministyczną. To znaczy, że możliwe jest przewidzenie kolejnych stanów takiej maszyny i bardzo dobrze. Gdyby tak nie było to niemożliwe byłoby zaprogramowanie takiej maszyny. Właściwie to nawet nie potrafię sobie wyobrazić, co by było... chyba nic by nie było. :-)
Wracając do tematu, z powyższego stwierdzenia wynika, że takim generatorem nie da się wytworzyć całkowicie losowego, nieskończonego ciągu liczb wykazujących losowość. Co byśmy nie robili zawsze będzie istniał jakiś okres takiej funkcji.
Dodatkowym problemem w niektórych aplikacjach jest to, że proces jest przewidywalny. To znaczy, że znając implementację można przewidzieć kolejną liczbę losową na podstawie poprzednich. Jest to wada całkowicie eliminująca taką funkcję generacji liczb losowych w kryptografi lub w grach losowych. Poniżej znajduje się tabelka porównująca dane typy generatorów.
2.1 Wybór najprostszego i jednocześnie najczęściej spotykanego
| Typ generatora | Szybkość | Przewidywalnosć | Okres sekwencji | Zew. hardware |
| Sprzętowy | Ograniczony możliwościami pomiarowymi | Całkowicie nieprzewidywalny | Nieskończony | Niezbędny |
| Pseudolosowy | Szybki | Przewidywalny (przynajmniej do pewnego stopnia) | Skończony | Nie potrzebny |
Tab. 2.1 - Porównanie typów generatorów
2.1 Wybór najprostszego i jednocześnie najczęściej spotykanego
Ze względu na to, że został już zaprezentowany przez Dondu generator sprzętowy, postanowiłem opracować prosty generator pseudolosowy.
Wybór padł na najprostszy (nie oszukujmy się, że przy AVRach potrzebujemy Bóg wie jakich rozwiązań), czyli Linear Congruential Generator (LCG), po polsku będzie to brzmiało jako przystający generator liniowy.
Jego podstawową zaletą jest prostota. Co automatycznie przekłada się na szybkość. Dodatkowo jest łątwy w implementacji i zużywający mało zasobów. Jako ciekawostkę należy nadmienić, że polecenie rand() to właśnie tego typu “generator”. Przejdźmy zatem od ogółu do szczegółu.
2.2 Opis teoretyczny
Jak już wcześniej powiedziałem przedstawiony generator odznacza się prostotą. Cały algorytm generowania następnej liczby opisuje poniższe równanie:

X n – jest to obecny stan generatora,
X n+1 –następny stan,
a oraz c są stałe.
a oraz c są stałe.
Liczbę pseudolosową otrzymujemy poddając stan następny operacji modulo:
m jest stałą.
Stałe w oby powyższych równaniach nie są jednak dowolne. Powinny spełniać następujące relacje:

X0 – nazywane jest “seed”, co po angielsku oznacza ziarenko, z tego właśnie ziarenka “wykiełkuje” sekwencja liczb pseudolosowych.
Właściwie to wszytko. Nic więcej nie stoi za funkcją rand(). Cała sprawa rozchodzi się teraz o to, żeby tak wybrać wartości a,c,m by uzyskać jak najdłuższy okres i by w ten sposób jak najbardziej przybliżyć naszą funkcję do prawdziwie losowej.
Niestety dobór odpowiednich wartości samemu jest porównywalne właściwie do sztuki. Ja w swoim rozwiązaniu posłużyłem się dostępnymi wartościami poszczególnych parametrów (ułatwiło to sprawę niesamowicie :D). Parametry zostały “ściągnięte” z [2].
Użyte przeze mnie parametry:

3. Realizacja
Tab. 2.2 - Wartosci parametrów
użyte w mojej implementacji
3. Realizacja
Ponieważ znamy już całą teorię stojącą za generowaniem liczb pseudolosowych należało przystąpić do wcielenia algorytmów w kod. By móc porównać jakość mojej implementacji z implementacją biblioteczną należało ustalić jakiś punkt odniesienia. Takim punktem była sama funkcja rand(). Przejdźmy zatem do przedstawienia i omówienia kodów.
3.1 Program na komputerze napisany z wykorzystaniem funkcji rand()
Poniżej znajduje się cały kod dla aplikacji generującej sekwencję liczb losowych o zadanej długości, jednocześnie zapisując ją do pliku.
Właściwie to nie ma co nawet za bardzo omawiać. Tworzymy plik i upychamy do niego sekwencję liczb losowych. Zamykamy plik i kończymy program.
#include <iostream>
#include <fstream>
#include <stdint.h>
#include <cstdlib>
using namespace std;
int main ( )
{
int N=1000000;
fstream plik ( " rand().dat", ios::out | ios::trunc ) ;
for ( int i =0; i<N; i++)
{
plik <<(rand()&0xffff )<<endl ; // liczba typu uint16_t
}
plik.close();
return 0 ;
}
Właściwie to nie ma co nawet za bardzo omawiać. Tworzymy plik i upychamy do niego sekwencję liczb losowych. Zamykamy plik i kończymy program.
3.2 Własna implementacja generatora napisana dla komputera.
Zacząłem od aplikacji na komputerze ze względu na to, że cały proces testowania, kompilacji itd. zajmuje mniej czasu niż pisanie aplikacji od razu na AVR. Zwłaszcz, że nie wykorzystuje tutaj żadnego sprzętu a jedynie tworzę jedną funkcję.
Dodatkowo trochę naciągnąłem zasady, ponieważ postanowiłem, że skoro jest to generator pseudolosowy i to do tego najprostszy z możliwych to powinien oferować coś w zamian. Dlatego mój generator losuje liczby z zakresu 0-0xffff, czyli inaczej mówiąc liczby 16 bitowe.
Teoretycznie są to dwie liczby 8–biowe, losowane jednocześnie. Jednak dla zwiększenia niezawodności zalecam wycinanie liczby ze “środka”. To znaczy:
Warto dodać, że zastosowana przeze mnie wartość m= 232 czyli dokładnie tyle, co liczba 32–bitowa. Dzięki temu niepotrzebna stała się operacja modulo i odpadła jedna 32–bitowa stała.
#include <iostream>
#include <fstream>
#include <stdint.h>
using namespace std;
//---Poczatek generatora --------------------------------------------
uint32_t stan_poprzedni=7; //Przy inicjalizacji bedzie to ’seed’
const uint32_t a=22695477 , c=1;
uint16_t losuj()
{
stan_poprzedni=(a stan_poprzedni+c );
return ( stan_poprzedni>>15)&0xffff;
}
//---Koniec generatora-------------------------------------------
const int N=10000000; // Ilosc liczb wyrzuconych do pliku
main ( )
{
fstream plik_wyjsciowy ( "data.dat" , ios::trunc | ios::out ) ;
for ( int i =0; i<N; i++)
{
plik_wyjsciowy<<losuj()<<endl ;
}
plik_wyjsciowy.close();
return 0 ;
}
3.3 Własna implementacja generatora napisana dla mikrokontrolera
Powiem szczerze, że specjalnie tak napisałem kod dla aplikacji komputerowej, żeby teraz go bezczelnie ściągnąć metodą kopypastego (znana również jako copy&paste).
Jak już wspomniałem wcześniej mikrokontroler był połączony z komputerem poprzez UART. Od strony komputera uruchomiłem program PuTTY. Po zakończeniu przesyłania wyników (trochę to jednak trwa...) zapisywałem log z trasmisji i miałem gotowy plik z sekwencją liczb. Warto wspomnieć, że PuTTY dopisuje w pierwszej linijce swój nagłówek. Jest tam informacja z datą i godziną. Dla mnie to nie było do niczego potrzebne dlatego tą lininię zawsze usuwałem.
/*******************************************************************
* EPP - Efektywne Planowanie Projektu (cykl artykułów)
* GENERATOR LICZB LOSOWYCH z wykorzystaniem przetwornika ADC
*
* autor: miszcz310
* styczen 2012
* Mikrokontrolery - Jak zacząć?
* http://mikrokontrolery.blogspot.com
*
* kod dla: Atmega8, zegar 8MHz
*******************************************************************/
#include <avr/io.h>
#include <util/delay.h>
#include <avr/interrupt.h>
#include<stdio.h>
#include<inttypes.h>
//---Poczatek generatora----------------------------------
unsigned int stan_poprzedni=1; //Przy inicjalizacji bedzie to 'seed'
const unsigned int a=22695477, c=1;
uint8_t losuj()
{
stan_poprzedni=(a*stan_poprzedni+c);
return stan_poprzedni%257;
}
//-----Koniec generatora----------------------------------
int main(void)
{
losuj();
while(1){}
}
Plik wraz z obsługą UART: main.cJak już wspomniałem wcześniej mikrokontroler był połączony z komputerem poprzez UART. Od strony komputera uruchomiłem program PuTTY. Po zakończeniu przesyłania wyników (trochę to jednak trwa...) zapisywałem log z trasmisji i miałem gotowy plik z sekwencją liczb. Warto wspomnieć, że PuTTY dopisuje w pierwszej linijce swój nagłówek. Jest tam informacja z datą i godziną. Dla mnie to nie było do niczego potrzebne dlatego tą lininię zawsze usuwałem.
3.4 Testy i porównanie otrzymanych wyników
Testy polegały polegały na wyznaczeniu histogramów i stwierdzenie na “oko” czy są dobre. Dzięki dobrym wynikom jakie otrzymałem udało mi się nawet wyznaczyć niepewność rozkładu prawdopodobieństwa. Wykorzystałem dwa rodzaje histogramów jedno i dwuwymiarowy. Jednowymiarowe histogramy pomogły ocenić równomierność rozkładów, histogramy dwuwymiarowe pozwoliły ocenić czy w sekwencjach nie występują bliskozasięgowe korelacje. Już na wstępnie mogę powiedzieć, że można spokojnie przyjąć, iż wszystkie rozkłady są równomierne. Co więcej w otrzymanych sekwencjach nie stwierdziłem żadnych bliskich korelacji.
Program oparty o funkcję rand()
Poniżej znajduje się histogram z 107 wylosowanych liczb (plik z danymi waży jakieś ~55MB). Na osi OX znajdują się wszystkie możliwe do wylosowania liczby, natomiast na osi OY ile razy się powtórzyły.

Co prawda może ten wykres nie przypomina lini prostej (rozkład równomierny). Jednak należy zauważyć, że oś OY nie zaczyna się w zerze. Gdyby zaczynała się w zerze, to prawdopodobnie poprzez rozdzielczość obrazka oglądalibyśmy linię prostą.
Przeprowadziłem dopasowanie, do powyższego histogramu wielomianu zerowego stopnia,
f(x)=A A–(wartość stała), poniżej znajduje się rysunek przedstawiający dopasowanie:

Wartość parametru dopasowania wyniósł: 39060,8 ± 12,3524 . Z tego dopasowania wynikało by, że niepewość niedopasowania wyniosła zaledwie 0,03%(!), co jest wartością bardzo małą. Dlatego wydało mi się, że należy posłużyć się inną wielkością. Nazwałem ją “błędem nierównomierności”.
Oszacujmy zatem “błąd równomierności” - przez takie stwierdzenie rozumiem maksymalną liczbę powtórzeń odjąć minimalną liczbę powtórzeń i wszystko podzielone przez 2.
Dla przedstawionego powyżej przypadku różnica wynosi ok. 1300 powtórzeń. Po podzieleniu na dwa wychodzi 650 powtórzeń. Średnia liczba powtórzeń dla każdej liczby wynosi około 39060 powtórzeń.
Błąd wynosi zatem:

Tą wartość będę porównywał z wynikami z mojej implementacji, ponieważ według mnie lepiej odzwierciedla faktyczną nierównomierność. Ta wartość wydaje się mała jednak przy niektórych zastosowaniach może być duża (nie jestem sobie w stanie na razie wyobrazić dla jakiego zastosowania, dla którego ten tym generatora jest stosowany ta wartość mogłaby uchodzić za znaczącą).
Przyjrzyjmy się zatem czy nasze dane nie są ze sobą skorelowane. Posłużyłem się do tego dwuwymiarowym histogramem. W tym przypadku histogram również zlicza powtórzenia, jednak punktów, a nie liczb. Kolejne punkty są tworzone w następujący sposób.

Jak czytać histogramy punktowe?
Każda liczba (oprócz pierwszej i ostatniej) tworzy współrzędną dla dwóch punktów. Jeżeli występowałaby jakaś korelacja pomiędzy liczbami to znaczy, że liczby byłyby np. raz duża raz mała, to na histogramie byłoby to widoczne jako dwie wyższe wyspy wyróżniające się z tła. Dla danych nieskorelowanym powinniśmy obserwować w idealnym przypadku jeden kolor wszystkich pikseli.
 Zobaczmy zatem co z tego wyszło (rys. obok). No ja przyznam się szczerze, że widzę tu morze zieloności. Co prawda widać pewne odchyły od koloru zielonego, ale nie widać żadnych dominujących miejsc, które świadczyłyby o wspomnianych wcześniej korelacjach.
Zobaczmy zatem co z tego wyszło (rys. obok). No ja przyznam się szczerze, że widzę tu morze zieloności. Co prawda widać pewne odchyły od koloru zielonego, ale nie widać żadnych dominujących miejsc, które świadczyłyby o wspomnianych wcześniej korelacjach.
Oczywiście można spekulować, że jest jakiś niewidoczny efekt i należałoby wydłużyć sekwencję. Jest to prawda tylko, że żeby mieć pewność, że się coś zobaczy należałoby tę sekwencję wydłużyć w nieskończoność. :-)
Histogram został wykonany dla 107 liczb, szczerze wątpię żeby ktoś potrzebował na codzień tak długie sekwencji liczb losowych. Ponadto przypuszczam, że zwiększenie sekwencji o kolejne 107 nie wykazało by jeszcze żadnej korelacji.
Program oparty o moją implementację na komputer
Poniżej przedstawiony został jednowymiarowy histogram dla danych uzyskanym za pomocą mojej implementacji funkcji losującej.

Cóż tu można powiedzieć, w sumie wygląda podobnie jak dla funkcji rand(). Przypominam, że oś OY nie zaczyna się w zerze. Przejdźmy do oceny ilościowej.

By móc porównać powyższy histogram z tym z poprzedniego punktu potrzebna nam wartość dopasowania wraz z niepewnością. Wartość dopasowania wyniosła 39060.9 ± 12.3524. Powiem szczerze, że na początku temu nie wierzyłem i próbowałem różnych metod dopasowania, ale zawsze dostawałem to samo (przypomnę, że do dopasowań używam frameworku root [3]).
Dopasowanie wartości średniej różni się tylko 0,1. Przypominam, że jest to wartość liczby powtórzeń, która musi być liczbą naturalną lub zerem. Z tego by wynikało, że jakość funkcji rand() i mojej implementacji są właściwie identyczne.
Zobaczmy jak wygląda mój “błąd nierównomierności”. Różnica skrajnych wartości wynosi ok. 1200 powtórzeń, wartość średnia wynosi 39060, zatem:

Z tego wynikałoby nawet, że moja implementacja odznacza się mniejszą nierównomiernością, jednak przewaga jest zaniedbywalnie mała. Myślę, że uczciwie można stwierdzić remis.
Powiem szczerze, że nie spodziewałem się, że tak prosty sposób generacji liczb losowych zapewni tak dobry wynik.
 Jak już wcześniej wspomniałem, dla tego typu generatorów prawdziwym testem jest test wielowymiarowy. Obok przedstawiłem histogram dwuwymiarowy, otrzymany w taki sam sposób jak w poprzednim punkcie, tylko z pomocą innych danych.
Jak już wcześniej wspomniałem, dla tego typu generatorów prawdziwym testem jest test wielowymiarowy. Obok przedstawiłem histogram dwuwymiarowy, otrzymany w taki sam sposób jak w poprzednim punkcie, tylko z pomocą innych danych.
Znowu ciężka sprawa, ponieważ nie wymyśliłem jakiejś niezleżnej metody oceny, niż “na oko”. Znaczy no mógłbym dopasować płaszczyznę, jednak niepewności dostarczane przez root'a są moim zdaniem nie miarodajne. Dlatego pozostanę przy metodzie "Π⋅drzwi". Dla mnie znowu ten histogram jak w przypadku tego z punktu poprzedniego stanowi to morze zieloności. Nie odróżniłbym ich gdyby mi przedstawiono oba obok siebie bez opisu, który został uzyskany, z których danych. Dlatego ten test również zaliczam.
Program oparty o moją implementację na atmegę
No wreszcie to na co wszyscy czekali. Tutaj muszę się od razu przyznać, nie miałem cierpliwości żeby wyczekać, aż 107 liczb zostanie wygenerowanych przez atmege i liczba po liczbie przesłanych przez UART. Dlatego zmniejszyłem tę liczbę o połowę. Pięć milionów liczb moim zdaniem też powinno wystarczyć do oceny funkcji generującej. Dodam, że to wygenerowanie i przesłanie trwało około 45 minut.

Znowu widzimy histogram jednowymiarowy. Co prawda kształt histogramu się różni, jednak zakres wartości powtórzeń jest właściwie ten sam tylko podzielony przez 2 (spowodowane jest to dwa razy mniejszą liczbą danych). Poniżej ten sam histogram z dopasowaniem.

Dopasowana wartość parametru wyniosła 19529.7 ± 8.7343. Znowu niepewność wzięta trochę z sufitu. Zauważmy, że jeżeli zaokrąglimy tę wartość do 19530 i pomnożymy przez dwa, to 19530 ⋅ 2=39060, czyli dokładnie tyle, co w poprzednich punktach. Nie ma się co dziwić, przecież to ten sam kod tylko na innej platformie.
Oszacujmy teraz “błąd nierówności”, różnica ekstremalnych wartości wynosi 800, co daje nam:

No teraz błąd jest większy w jakiś mierzalny sposób w porównaniu do poprzednich przypadków. Może być to spowodowane różną długością sekwencji. Uważam, jednak, że różnice rzędu 0,5% są zaniedbywalnie małe.
 Patrząc na ten histogram uważam, że jedyne po czym mógłbym go odróżnić od wcześniej przedstawionych to tylko liczba zliczeń na legendzie koloru. Dlatego ten test również zaliczam.
Patrząc na ten histogram uważam, że jedyne po czym mógłbym go odróżnić od wcześniej przedstawionych to tylko liczba zliczeń na legendzie koloru. Dlatego ten test również zaliczam.
Fajnie tak samemu sobie zaliczać... ale tak na poważnie to starałem się wykonać wszystkie testy tak rzetelnie jak tylko potrafiłem, jeżeli masz jakieś (konstruktywne) zastrzeżenia to proszę o kontakt.
Podsumowanie
Udało się uzyskać postawiony cel, to znaczy zasymulować działanie funkcji rand(). Implementacja na mikokontroler przeszła pomyślnie testy porównawcze. Najciekawsze zostawiłem na sam koniec. Przy implementacji samej definicji funkcji losującej plus jedno wywołanie przed pętlą główną, oto co dostałem po kompilacji:
Z powyższego wynika, że moja implementacja zajmuje w pamięci 268 bajtów. Porównajmy tę wartość do tej, gdzie mamy “pusty program”:
Program zajmuje 62 bajty. Po odjęciu dostajemy 268-62=206B . Z tego wynika, że moja implementacja zajmuje ponad dwa razy mniej pamięci od funkcji rand(). Założenie spełnione.
Dodatkowo otrzymaliśmy funkcję dającą liczby z przedziału 0-0xFFFF. Jest to mniejszy przedział niż dla funkcji rand(), ale też większy od implementacji Dondu (akurat w jego implementacji to nie problem rozszerzyć lub zmniejszyć rozmiar bitowy otrzymywanej liczby).
Jednak podstawową zaletą tej implementacji jest to, że nie wykorzystujemy żadnych peryferii. Co powoduje, że możemy jej używać w mikrokontrolerach pozbawionych ADC. Dodatkowo kolejne liczby są gotowe tam gdzie chcemy, nie trzeba czekać zadanego okresu czasu na nową wartość.
Największą wadą tego generatora jest to, że otrzymujemy liczby pseudolosowe, generator Dondu dostarcza prawdziwie losowe liczby. Drugą wadą jest to, że bardziej obciąża rdzeń. Wykonujemy tu w końcu kilka mnożeń liczb 32–bitowych.
Przedstawione rozwiązanie jest według mnie nie tyle konkurencyjne o ile uzupełniające do rozwiązania zaprezentowanego przez Dondu.
Bibliografia:
[1] http://pl.wikipedia.org/wiki/Generator_liczb_losowych
[2] http://en.wikipedia.org/wiki/Linear_congruential_generator
[3] http://root.cern.ch/drupal/
Poniżej znajduje się histogram z 107 wylosowanych liczb (plik z danymi waży jakieś ~55MB). Na osi OX znajdują się wszystkie możliwe do wylosowania liczby, natomiast na osi OY ile razy się powtórzyły.

Co prawda może ten wykres nie przypomina lini prostej (rozkład równomierny). Jednak należy zauważyć, że oś OY nie zaczyna się w zerze. Gdyby zaczynała się w zerze, to prawdopodobnie poprzez rozdzielczość obrazka oglądalibyśmy linię prostą.
Przeprowadziłem dopasowanie, do powyższego histogramu wielomianu zerowego stopnia,
f(x)=A A–(wartość stała), poniżej znajduje się rysunek przedstawiający dopasowanie:

Wartość parametru dopasowania wyniósł: 39060,8 ± 12,3524 . Z tego dopasowania wynikało by, że niepewość niedopasowania wyniosła zaledwie 0,03%(!), co jest wartością bardzo małą. Dlatego wydało mi się, że należy posłużyć się inną wielkością. Nazwałem ją “błędem nierównomierności”.
Oszacujmy zatem “błąd równomierności” - przez takie stwierdzenie rozumiem maksymalną liczbę powtórzeń odjąć minimalną liczbę powtórzeń i wszystko podzielone przez 2.
Dla przedstawionego powyżej przypadku różnica wynosi ok. 1300 powtórzeń. Po podzieleniu na dwa wychodzi 650 powtórzeń. Średnia liczba powtórzeń dla każdej liczby wynosi około 39060 powtórzeń.
Błąd wynosi zatem:
Tą wartość będę porównywał z wynikami z mojej implementacji, ponieważ według mnie lepiej odzwierciedla faktyczną nierównomierność. Ta wartość wydaje się mała jednak przy niektórych zastosowaniach może być duża (nie jestem sobie w stanie na razie wyobrazić dla jakiego zastosowania, dla którego ten tym generatora jest stosowany ta wartość mogłaby uchodzić za znaczącą).
Przyjrzyjmy się zatem czy nasze dane nie są ze sobą skorelowane. Posłużyłem się do tego dwuwymiarowym histogramem. W tym przypadku histogram również zlicza powtórzenia, jednak punktów, a nie liczb. Kolejne punkty są tworzone w następujący sposób.
Jak czytać histogramy punktowe?
Każda liczba (oprócz pierwszej i ostatniej) tworzy współrzędną dla dwóch punktów. Jeżeli występowałaby jakaś korelacja pomiędzy liczbami to znaczy, że liczby byłyby np. raz duża raz mała, to na histogramie byłoby to widoczne jako dwie wyższe wyspy wyróżniające się z tła. Dla danych nieskorelowanym powinniśmy obserwować w idealnym przypadku jeden kolor wszystkich pikseli.

Oczywiście można spekulować, że jest jakiś niewidoczny efekt i należałoby wydłużyć sekwencję. Jest to prawda tylko, że żeby mieć pewność, że się coś zobaczy należałoby tę sekwencję wydłużyć w nieskończoność. :-)
Histogram został wykonany dla 107 liczb, szczerze wątpię żeby ktoś potrzebował na codzień tak długie sekwencji liczb losowych. Ponadto przypuszczam, że zwiększenie sekwencji o kolejne 107 nie wykazało by jeszcze żadnej korelacji.
Program oparty o moją implementację na komputer
Poniżej przedstawiony został jednowymiarowy histogram dla danych uzyskanym za pomocą mojej implementacji funkcji losującej.
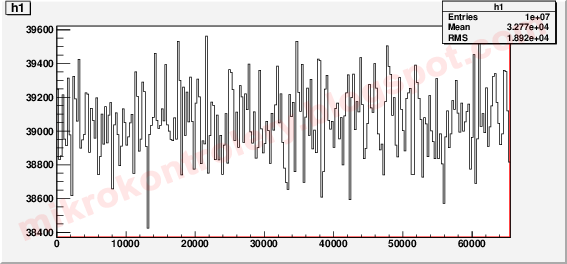
Cóż tu można powiedzieć, w sumie wygląda podobnie jak dla funkcji rand(). Przypominam, że oś OY nie zaczyna się w zerze. Przejdźmy do oceny ilościowej.

By móc porównać powyższy histogram z tym z poprzedniego punktu potrzebna nam wartość dopasowania wraz z niepewnością. Wartość dopasowania wyniosła 39060.9 ± 12.3524. Powiem szczerze, że na początku temu nie wierzyłem i próbowałem różnych metod dopasowania, ale zawsze dostawałem to samo (przypomnę, że do dopasowań używam frameworku root [3]).
Dopasowanie wartości średniej różni się tylko 0,1. Przypominam, że jest to wartość liczby powtórzeń, która musi być liczbą naturalną lub zerem. Z tego by wynikało, że jakość funkcji rand() i mojej implementacji są właściwie identyczne.
Zobaczmy jak wygląda mój “błąd nierównomierności”. Różnica skrajnych wartości wynosi ok. 1200 powtórzeń, wartość średnia wynosi 39060, zatem:
Z tego wynikałoby nawet, że moja implementacja odznacza się mniejszą nierównomiernością, jednak przewaga jest zaniedbywalnie mała. Myślę, że uczciwie można stwierdzić remis.
Powiem szczerze, że nie spodziewałem się, że tak prosty sposób generacji liczb losowych zapewni tak dobry wynik.

Znowu ciężka sprawa, ponieważ nie wymyśliłem jakiejś niezleżnej metody oceny, niż “na oko”. Znaczy no mógłbym dopasować płaszczyznę, jednak niepewności dostarczane przez root'a są moim zdaniem nie miarodajne. Dlatego pozostanę przy metodzie "Π⋅drzwi". Dla mnie znowu ten histogram jak w przypadku tego z punktu poprzedniego stanowi to morze zieloności. Nie odróżniłbym ich gdyby mi przedstawiono oba obok siebie bez opisu, który został uzyskany, z których danych. Dlatego ten test również zaliczam.
Program oparty o moją implementację na atmegę
No wreszcie to na co wszyscy czekali. Tutaj muszę się od razu przyznać, nie miałem cierpliwości żeby wyczekać, aż 107 liczb zostanie wygenerowanych przez atmege i liczba po liczbie przesłanych przez UART. Dlatego zmniejszyłem tę liczbę o połowę. Pięć milionów liczb moim zdaniem też powinno wystarczyć do oceny funkcji generującej. Dodam, że to wygenerowanie i przesłanie trwało około 45 minut.

Znowu widzimy histogram jednowymiarowy. Co prawda kształt histogramu się różni, jednak zakres wartości powtórzeń jest właściwie ten sam tylko podzielony przez 2 (spowodowane jest to dwa razy mniejszą liczbą danych). Poniżej ten sam histogram z dopasowaniem.

Dopasowana wartość parametru wyniosła 19529.7 ± 8.7343. Znowu niepewność wzięta trochę z sufitu. Zauważmy, że jeżeli zaokrąglimy tę wartość do 19530 i pomnożymy przez dwa, to 19530 ⋅ 2=39060, czyli dokładnie tyle, co w poprzednich punktach. Nie ma się co dziwić, przecież to ten sam kod tylko na innej platformie.
Oszacujmy teraz “błąd nierówności”, różnica ekstremalnych wartości wynosi 800, co daje nam:
No teraz błąd jest większy w jakiś mierzalny sposób w porównaniu do poprzednich przypadków. Może być to spowodowane różną długością sekwencji. Uważam, jednak, że różnice rzędu 0,5% są zaniedbywalnie małe.
Zatem generator uruchomiony na ATmedze uważam, za równoważny
z tymi uruchamianymi na komputerze.

Fajnie tak samemu sobie zaliczać... ale tak na poważnie to starałem się wykonać wszystkie testy tak rzetelnie jak tylko potrafiłem, jeżeli masz jakieś (konstruktywne) zastrzeżenia to proszę o kontakt.
Podsumowanie
Udało się uzyskać postawiony cel, to znaczy zasymulować działanie funkcji rand(). Implementacja na mikokontroler przeszła pomyślnie testy porównawcze. Najciekawsze zostawiłem na sam koniec. Przy implementacji samej definicji funkcji losującej plus jedno wywołanie przed pętlą główną, oto co dostałem po kompilacji:
| text | data | bss | dec | hex | filename |
| 268 | 12 | 0 | 280 | 118 | program.elf |
Z powyższego wynika, że moja implementacja zajmuje w pamięci 268 bajtów. Porównajmy tę wartość do tej, gdzie mamy “pusty program”:
| text | data | bss | dec | hex | filename |
| 62 | 0 | 0 | 62 | 3e | program.elf |
Program zajmuje 62 bajty. Po odjęciu dostajemy 268-62=206B . Z tego wynika, że moja implementacja zajmuje ponad dwa razy mniej pamięci od funkcji rand(). Założenie spełnione.
Dodatkowo otrzymaliśmy funkcję dającą liczby z przedziału 0-0xFFFF. Jest to mniejszy przedział niż dla funkcji rand(), ale też większy od implementacji Dondu (akurat w jego implementacji to nie problem rozszerzyć lub zmniejszyć rozmiar bitowy otrzymywanej liczby).
Jednak podstawową zaletą tej implementacji jest to, że nie wykorzystujemy żadnych peryferii. Co powoduje, że możemy jej używać w mikrokontrolerach pozbawionych ADC. Dodatkowo kolejne liczby są gotowe tam gdzie chcemy, nie trzeba czekać zadanego okresu czasu na nową wartość.
Największą wadą tego generatora jest to, że otrzymujemy liczby pseudolosowe, generator Dondu dostarcza prawdziwie losowe liczby. Drugą wadą jest to, że bardziej obciąża rdzeń. Wykonujemy tu w końcu kilka mnożeń liczb 32–bitowych.
Przedstawione rozwiązanie jest według mnie nie tyle konkurencyjne o ile uzupełniające do rozwiązania zaprezentowanego przez Dondu.
Bibliografia:
[1] http://pl.wikipedia.org/wiki/Generator_liczb_losowych
[2] http://en.wikipedia.org/wiki/Linear_congruential_generator
[3] http://root.cern.ch/drupal/




Brak komentarzy:
Prześlij komentarz